[Oracle] 정규식 사용법 쉽게 설명 (REGEXP)
- 데이터베이스/오라클
- 2022. 11. 28.
오라클 10g부터 정규식을 사용할 수 있도록 함수가 추가되었다. 정규식을 사용하면 문자열을 패턴으로 찾거나 자를 수 있기 때문에 기존의 복잡하게 구현된 쿼리문을 정규식 함수를 사용하여 간단하게 처리할 수 있다. 일반적인 프로그래밍 언어에서 사용하는 정규식을 그대로 사용할 수 있으나, 전방 탐색 또는 후방 탐색 등 일부 지원하지 않는 패턴이 있다. 아래의 기본 기능을 이해했다면 정규식을 응용하여 사용하는데 어렵지 않을 것이다.
| 목차 |
기본 메타 문자
| 메타 문자 | 설명 |
| . | 임의의 한 문자 |
| | | OR과 동일 (왼쪽 또는 오른쪽과 일치) |
| [] | 문자 클래스 |
| [-] | 문자 범위 (0-9, a-z, A-Z, 가-힝) |
| [^] | 부정 문자 클래스 |
| \ | 다음에 오는 문자를 이스케이프 (메타 문자를 일반 문자로) |
| ^ | 문자열의 시작과 일치 |
| $ | 문자열의 끝과 일치 |
기본 메타 문자의 기능만 이해해도 정규식을 익히는데 아주 많은 도움이 된다.
아래는 아주 단순한 예제지만 패턴을 조금씩 바꿔가면서 실습을 하면 쉽게 이해할 수 있을 것이다.
문자열 찾기
SELECT REGEXP_SUBSTR('oracle database', 'oracle') AS regex1
, REGEXP_SUBSTR('oracle database', 'database') AS regex2
, REGEXP_SUBSTR('oracle database', 'sql') AS regex3
FROM dual
 |
정규식 패턴에 문자열을 입력하면 대상 문자열에서 정확히 일치하는 문자열이 있을 경우 해당 문자열이 반환된다.
"oracle"과 "database" 문자열은 대상 문자열에 존재하기 때문에 반환되고 "sql"은 존재하기 않기 때문에 찾지 못한다. 보통 정규식 패턴은 메타 문자를 사용해서 작성하지만 문자열만 입력했을 경우 동작하는 방식을 설명하기 위한 예시이다.
점( . ) : 임의의 한 문자
SELECT REGEXP_SUBSTR('oracle database', '.') AS regex1
, REGEXP_SUBSTR('oracle database', '.', 1, 2) AS regex2
, REGEXP_SUBSTR('oracle database', '.', 1, 3) AS regex3
FROM dual
 |
메타 문자 점(.)은 임의의 한 문자(숫자, 영문자, 특수문자 등)를 의미한다. (점은 모든 문자를 의미)
점을 세번(...) 사용하면 임의의 연속된 3개의 문자를 의미한다. (예, ora, rac, acl, cle, le , e d)
파이프( | ): OR과 동일 (왼쪽 또는 오른쪽과 일치)
SELECT REGEXP_SUBSTR('oracle database', 'a|b|c') AS regex1
, REGEXP_SUBSTR('oracle database', 'a|b|c', 1, 2) AS regex2
, REGEXP_SUBSTR('oracle database', 'a|b|c', 1, 3) AS regex3
FROM dual
 |
파이프(|)는 WHERE 절에서 OR과 비슷하다고 생각하면 된다.
'문자열|문자열|문자열|문자열'과 같은 방식으로 사용하며 파이프로 구분된 문자 열중 하나와 일치하면 해당 문자열이 반환된다.
위의 예제의 패턴을 'ab|ac|ad' 이렇게 변경하면 'oracle database' 두 개의 문자열이 일치하게 된다.
대괄호( [] ) : 문자 클래스
SELECT REGEXP_SUBSTR('oracle database', '[abc]') AS regex1
, REGEXP_SUBSTR('oracle database', '[abc]', 1, 2) AS regex2
, REGEXP_SUBSTR('oracle database', '[abc]', 1, 3) AS regex3
FROM dual
 |
문자 클래스 대괄호([]) 안의 문자는 문자 하나하나가 OR로 인식한다고 생각하면 된다. a|b|c와 동일하다.
'[abcde]'로 패턴을 작성할 경우 'oracle database' 다섯 가지의 문자가 일치하게 된다.
대괄호 + 대시( [-] ) : 문자 범위 (0-9, a-z, A-Z, 가-힝)
SELECT REGEXP_SUBSTR('oracle database', '[a-c]') AS regex1
, REGEXP_SUBSTR('oracle database', '[a-c]', 1, 2) AS regex2
, REGEXP_SUBSTR('oracle database', '[a-c]', 1, 3) AS regex3
FROM dual
 |
문자 클래스에서 대시(-) 기호를 하용하여 연속된 문자의 범위를 지정할 수 있다. 문자 클래스는 대괄호 안의 모든 문자가 OR로 인식하지만, 대시 기호를 사용하여 범위를 지정하면 해당 범위가 하나의 문자를 지칭하게 된다.
위의 예제 '[a-c]'의 패턴은 a, b, c의 소문자를 지칭한다. '[abc]'와 동일하다.
[0-9] : 숫자 (0 or 1 or 2 or 3 or 4 ...)
[a-z] : 소문자 (a or b or c or d or e ...)
[A-Z] : 대문자 (A or B or C or D or E ...)
[가-힝] : 한글
문자 클래스에서 문자 범위를 조합해서 사용할 수 있다.
'[a-zA-Z]' 소문자+ 소문자를 지정할 경우 'abcd1234EFGH' 소문자 및 대문자를 찾고, '[0-9a-zA-Z]' 숫자+소문자+대문자를 지정할 경우 'abcd1234EFGH' 숫자, 소문자, 대문자를 모두 찾는다.
대괄호 + 앵커( [^] ) : 부정 문자 클래스
SELECT REGEXP_SUBSTR('oracle database', '[^abc]') AS regex1
, REGEXP_SUBSTR('oracle database', '[^abc]', 1, 2) AS regex2
, REGEXP_SUBSTR('oracle database', '[^abc]', 1, 3) AS regex3
FROM dual
 |
부정 문자 클래스는 문자 클래스 내부의 문자를 제외한 모든 문자를 찾는다.
위의 예제는 a, b, c 문자를 제외한 문자가 반환되며, 공백도 하나의 문자에 포함된다.
문자 클래스 시작에 앵커(^) 기호를 붙이면 된다.
역슬래시( \ ) : 메타 문자를 일반 문자로
SELECT REGEXP_SUBSTR('oracle database [21c]', '[21c]') AS regex1
, REGEXP_SUBSTR('oracle database [21c]', '\[21c\]') AS regex2
FROM dual
 |
메타 문자에 해당하는 문자를 검색하기 위해서는 이스케이프(\) 문자를 함께 사용해야 한다.
문자열에서 '[21c]' 문자열이 존재하는지 검색하기 위해서는 대괄호를 역슬래시와 함께 사용해야 한다.
앵커 ( ^ ) : 문자열의 시작과 일치
SELECT REGEXP_SUBSTR('oracle database', '^oracle') AS regex1
, REGEXP_SUBSTR('oracle database', '^database') AS regex2
FROM dual
 |
앵커(^)는 문자열의 시작을 의미한다.
'^oracle'은 문자열의 시작에 'oracle' 문자열이 존재하기 때문에 패턴이 일치하고, '^database'은 문자열의 시작에 'database' 문자열이 존재하지 않기 때문에 반환 값이 없다.
달러 ( $ ) : 문자열의 끝과 일치
SELECT REGEXP_SUBSTR('oracle database', 'oracle$') AS regex1
, REGEXP_SUBSTR('oracle database', 'database$') AS regex2
FROM dual
 |
달러($)는 문자열의 끝을 의미한다.
찾을 문자열 + 문자열의 끝($)에 해당하는 패턴을 찾는다.
수량자
| 메타 문자 | 설명 |
| * | 0회 또는 1회 이상 매치 |
| + | 1회 이상 매치 |
| ? | 0회 또는 1회 매치 |
| {n} | n번 매치 |
| {m, n} | 최소 m번, 최대 n번 매치 |
| {n,} | n번 이상 매치 |
수량자는 문자나 패턴의 반복 횟수를 지정하는 메타 문자이다.
아래의 예제는 단순 문자 하나에 수량자를 지정했지만, 문자 클래스(대괄호)나 그룹(괄호)에 많이 사용한다. 아래의 예제를 이해했다면 쉽게 응용할 수 있을 것이다.
별표 ( * ) : 0회 또는 1회 이상 매치
SELECT REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora*cle') AS regex1
, REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora*cle', 1, 2) AS regex2
, REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora*cle', 1, 3) AS regex3
FROM dual
 |
별표(*) 수량자는 바로 앞의 문자가 없거나 1회 이상 반복할 경우를 의미한다.
위의 예시는 'or + a* + cle'와 일치하는 문자열을 찾는다.
('a'가 'or'과 'cle' 문자열 사이에 없거나 1번 이상 반복될 경우)
플러스 ( + ) : 1회 이상 매치
SELECT REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora+cle') AS regex1
, REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora+cle', 1, 2) AS regex2
, REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora+cle', 1, 3) AS regex3
FROM dual
 |
플러스(*) 수량자는 바로 앞의 문자가 1회 이상 반복할 경우를 의미한다.
위의 예시는 'or + a+ + cle'와 일치하는 문자열을 찾는다.
('a'가 'or'과 'cle' 문자열 사이에 1번 이상 반복될 경우)
물음표 ( ? ) : 0회 또는 1회 매치
SELECT REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora?cle') AS regex1
, REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora?cle', 1, 2) AS regex2
, REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora?cle', 1, 3) AS regex3
FROM dual
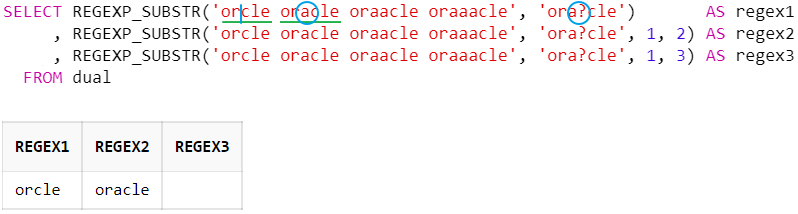 |
물음표(?) 수량자는 바로 앞의 문자가 없거나 1번 있는 경우를 의미한다.
위의 예시는 'or + a? + cle'와 일치하는 문자열을 찾는다.
('a'가 'or'과 'cle' 문자열 사이에 없거나 1번 있는 경우)
중괄호 ( {n} ) : n번 매치
SELECT REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora{2}cle') AS regex1
, REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora{2}cle', 1, 2) AS regex2
FROM dual
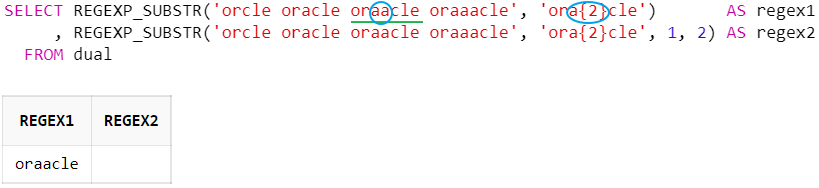 |
중괄호{n} 수량자는 바로 앞의 문자가 n회 반복할 경우를 의미한다.
위의 예시는 'or + a{2} + cle'와 일치하는 문자열을 찾는다.
('a'가 'or'과 'cle' 문자열 사이에 2회 반복될 경우)
중괄호 ( {m, n} ) : 최소 m번, 최대 n번 매치
SELECT REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora{2,3}cle') AS regex1
, REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora{2,3}cle', 1, 2) AS regex2
FROM dual
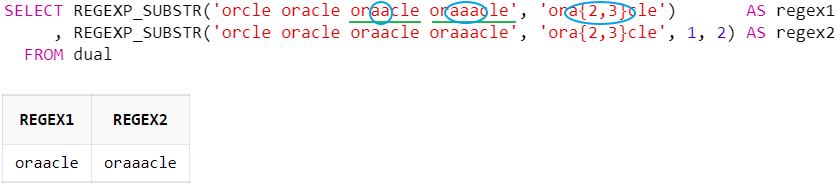 |
중괄호{m, n} 수량자는 바로 앞의 문자가 최소 m회, 최대 n회 반복할 경우를 의미한다.
위의 예시는 'or + a{2,3} + cle'와 일치하는 문자열을 찾는다.
('a'가 'or'과 'cle' 문자열 사이에 최소 2회, 최대 3회 반복될 경우)
중괄호 ( {n,} ) : n번 이상 매치
SELECT REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora{2,}cle') AS regex1
, REGEXP_SUBSTR('orcle oracle oraacle oraaacle', 'ora{2,}cle', 1, 2) AS regex2
FROM dual
 |
중괄호{n,} 수량자는 바로 앞의 문자가 n회 이상 반복할 경우를 의미한다.
위의 예시는 'or + a{2,} + cle'와 일치하는 문자열을 찾는다.
('a'가 'or'과 'cle' 문자열 사이에 2회 이상 반복될 경우)
수량자 응용 예제
SELECT REGEXP_SUBSTR('abbbb acccc adddd', 'a[cd]+') AS regex1
, REGEXP_SUBSTR('abbbb acccc adddd', 'a[cd]+', 1, 2) AS regex2
, REGEXP_SUBSTR('abc abcbc axbcbc', 'a(bc)+') AS regex3
, REGEXP_SUBSTR('abc abcbc axbcbc', 'a(bc)+', 1, 2) AS regex4
FROM dual
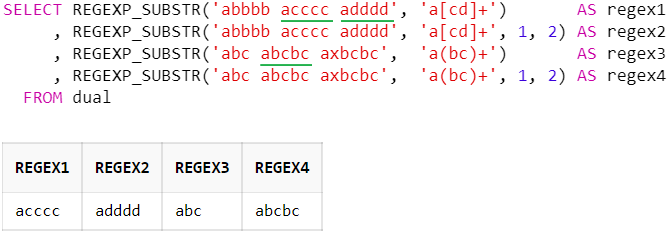 |
a[cd]+ : 문자열이 'a'로 시작하고 'c' 또는 'd'가 1회 이상 반복되는 패턴
a(bc)+ : 문자열이 'a'로 시작하고 패턴 그룹(문자열) 'bc'가 1회 이상 반복되는 패턴 (패턴 그룹은 아래 참고)
그룹과 역참조
| 메타 문자 | 설명 |
| () | 패턴 그룹 |
| \1 | 역참조 (\1: 패턴그룹1, \2: 패턴그룹2, \3: 패턴그룹3 ...) |
패턴 그룹과 역참조는 패턴이 조합된 상태에서 사용하는 메타 문자 이므로 조금 복잡해 보일 수 있다.
아래의 예제를 조금씩 변형해 보면서 연습해 보면 이해가 될 것이다.
패턴 그룹
SELECT REGEXP_SUBSTR('abc abbc abbbc', '(ab{2}c)|(ab{3}c)') AS regex1
, REGEXP_SUBSTR('abc abbc abbbc', '(ab{2}c)|(ab{3}c)', 1, 2) AS regex2
FROM dual
 |
문자열이나 패턴을 괄호로 묶으면 하나의 단위가 된다.
위의 예제는 2개의 패턴 그룹을 파이프(|) 메타 문자로 연결했으므로 2개의 패턴 중 일치하는 패턴이 있으면 찾는다.
역참조
SELECT REGEXP_SUBSTR('abc abbc abbbc', 'a(.)\1c') AS regex1
, REGEXP_SUBSTR('abc abbc abbbc', 'a(.)\1\1c') AS regex2
FROM dual
 |
역참조(\순번)는 앞의 패턴 그룹(괄호)의 값을 복사해서 사용할 수 있다.
'a' 다음에 오는 임의의 한 문자(.)는 'b'이며 \1로 한번 복사하면 'bb'이고 \1\1로 두 번 복사하면 abbb이다.
정규식 함수
| 함수명 | 설명 |
| REGEXP_SUBSTR | 일치하는 패턴의 문자열을 반환한다. |
| REGEXP_INSTR | 일치하는 패턴의 시작 위치를 정수로 반환한다. |
| REGEXP_LIKE | 패턴과 일치하면 True, 일치하지 않으면 False를 반환한다. |
| REGEXP_REPLACE | 일치하는 패턴을 특정 문자열로 치환한다. |
| REGEXP_COUNT | 일치하는 패턴의 횟수를 반환한다. |
아래의 포스팅을 참고하면 정규식을 이해하는데 조금 더 도움이 될 것이다.
[Oracle] 다중 LIKE 검색 방법 (정규식)
오라클에서 여러 개의 단어를 LIKE로 검색하기 위해서는 동적 쿼리를 사용하거나 LIKE를 OR로 묶어서 사용했다. Oracle 10g부터 정규식 함수가 추가 되었으며 그 중에서 REGEXP_LIKE 함수를 사용하여 다
gent.tistory.com
[Oracle] 다중 치환(REPLACE) 방법 (정규식)
오라클 REGEXP_REPLACE 다중(여러개) Replace(치환) 하는 방법 오라클 10g 부터 정규식 함수가 추가 되었다. 정규식을 사용하여 기존 함수보다 더 많은 기능을 수행한다.기존 Replace 함수를 사용하여 여러
gent.tistory.com
[Oracle] 문자열에서 특정 문자 개수 (정규식)
오라클에서 문자열에서 특정 문자의 개수를 구하기 위해서는 아래의 2가지 방법을 사용하면 쉽게 구할 수 있다. 특히 값을 특수문자로 구분하여 하나의 컬럼에 저장하였을 경우 값의 개수를 구
gent.tistory.com
[Oracle] 오라클 문자열 구분자 자르기 (정규식)
오라클에서 문자열의 특정 구분자를 기준으로 자르기 위해서는 SUBSTR, INSTR 함수를 사용한다. 그러나 오라클 10g부터 REGEXP_SUBSTR 정규식 함수를 사용하면 간편하게 문자열을 구분자로 자를 수 있다
gent.tistory.com
[Oracle] 문자열에서 한글만 추출 방법 (정규식)
오라클에서 칼럼의 문자열에서 한글이 아닌 문자를 제거하고 한글만 추출해야 하는 경우가 있다. 문자열에서 한글만 추출할 때는 정규식 함수를 사용하면 쉽게 해결된다. 오라클에서 정규식 함
gent.tistory.com
[Oracle] 문자열에서 괄호 문자 추출 방법 (정규식)
오라클에서 문자열에서 괄호 안의 텍스트, 글자, 문자, 숫자를 추출할 때는 정규식 함수를 사용하면 쉽게 추출할 수 있다. 그러나 오라클 9i 이하인 경우 정규식 함수를 사용할 수 없기 때문에 SUB
gent.tistory.com
[Oracle] 문자열에서 HTML 태그 값 추출 (정규식)
오라클에서 HTML 문자열 내부의 특정 태그 값을 추출하기 위해서는 정규식 함수를 사용하면 쉽게 해결된다. 정규식 함수는 Oracle 10g 이상에서 사용할 수 있으며, Oracle 11g 이상에서는 XMLTYPE 함수를
gent.tistory.com