[Oracle] 중복 데이터 하나만 남기고 제거 2가지 방법
- 데이터베이스/오라클
- 2022. 2. 16.
오라클에서 조회된 데이터에서 특정 칼럼을 기준으로 하나의 행만 조회해야 하는 경우가 있다. 중복된 칼럼의 데이터에서 그룹별로 최신의 행 하나만 가져오거나, 특정 칼럼으로 정렬하여 최상위 하나의 행만 조회할 때 아래의 2가지 방법을 사용할 수 있다. 아래의 방법은 행 전체를 중복 체크를 하여 제거하는 방법(DISTINCT)이 아니고 특정 칼럼을 기준으로 중복을 제거하는 방법이다.
그룹별로 순번을 지정하여 하나의 행만 추출
SELECT empno
, ename
, job
, hiredate
FROM (
SELECT empno
, ename
, job
, hiredate
, ROW_NUMBER() OVER(PARTITION BY job ORDER BY hiredate DESC) AS rn
FROM emp
)
WHERE rn = 1
ORDER BY job
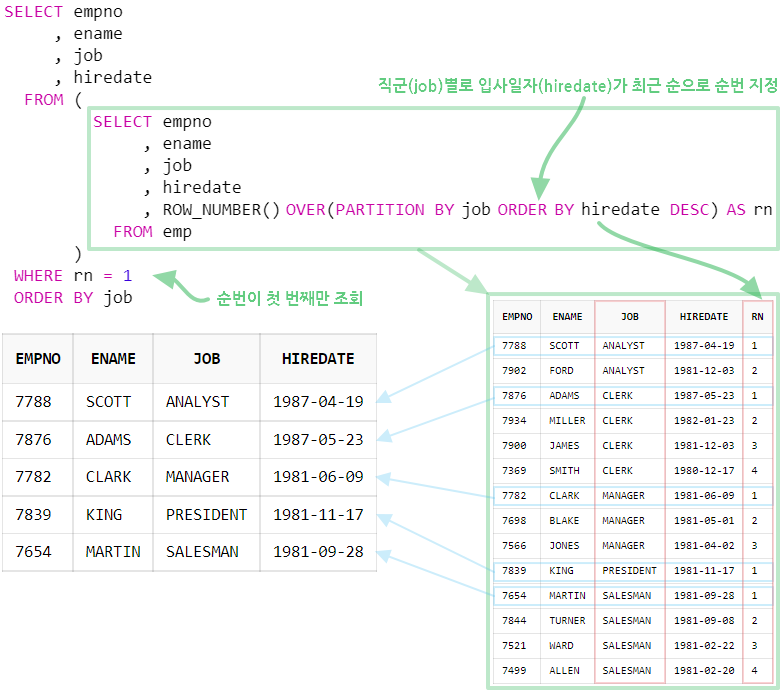 |
ROW_NUMBER 함수를 사용하여 직군(job) 별 최근 입사일자(hiredate) 순으로 순번을 부여한 후, 해당 데이터를 인라인 뷰로 사용하여 직군별 첫 번째 순번(rn=1)만 조회하는 방법이다.
위의 방법을 사용하면 GROUP BY 절이나 DISTINCT 키워드를 사용하지 않고도 특정 칼럼을 그룹으로 하나의 데이터만 조회를 할 수 있다.
그룹별로 MAX에 해당하는 행만 추출
SELECT a.empno
, a.ename
, a.job
, a.hiredate
FROM emp a
WHERE a.hiredate = (SELECT MAX(aa.hiredate)
FROM emp aa
WHERE aa.job = a.job)
ORDER BY a.job
 |
위의 예제는 직군(job) 별로 최근 입사일자(hiredate)를 조회하여 해당 직군의 가장 최근 입사일자에 해당하는 사원만 조회하는 방법이다. 직군별로 최근 입사일자가 동일한 사원이 존재한다면 2명 이상이 조회될 수도 있다.
그룹별로 MAX 값을 가져올 때 조인 칼럼(aa.job)에 인덱스가 존재하지 않는다면 속도가 느려질 수 있으니, 데이터가 많은 테이블인 경우 해당 칼럼에 인덱스가 존재하는지 미리 확인하는 것이 좋다.
▼ DISTINCT, GROUP BY 절을 사용하는 단순 중복제거 방법은 아래를 참고하면 된다.
[Oracle] 중복 제거 방법 (DISTINCT, GROUP BY)
오라클에서 데이터 조회 시 데이터 중복을 제거하기 위해서는 대표적으로 2가지 방법이 있다. DISTINCT 키워드를 사용하여 중복을 제거하는 방법과, GROUP BY 절을 사용하여 데이터 중복을 제거하는
gent.tistory.com
[Oracle] SELECT절에서 중복된 값 한번만 표시 방법
오라클 SQL에서 SELECT 된 값에서 이전 행의 값과 동일한 경우 중복된 값을 NULL로 처리하여 제거를 해야 하는 상황이 종종 발생한다. 대부분 애플리케이션 단에서 처리하면 쉽게 해결되지만, 쿼리
gent.tistory.com